Linked List (연결 리스트)
우선 List(리스트)는 데이터에 순서를 매겨둔 자료구조이다. 데이터들이 순서대로 쭉 늘어진 모양을 하고있다. 아직까지 이 데이터들은 차례대로 줄을 서고 있을 뿐 서로에 대해 모르는 상태이다.
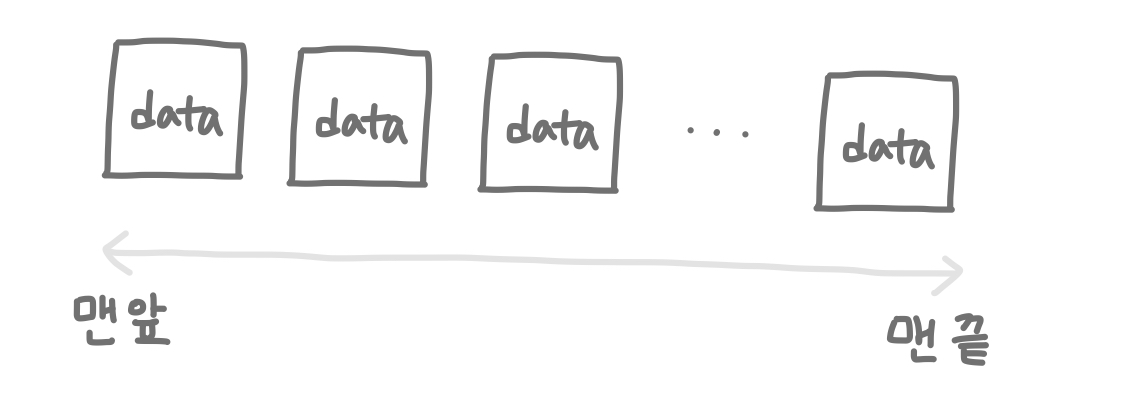
Linked List(연결 리스트)는 데이터들이 연락처를 주고받아 자기 뒤에있는 사람에게 연락을 할 수 있게 된 상태이다. 대신 누군가를 건너뛰거나 뒤를 돌아서 앞 사람에게 연락을 할 수는 없다. 오직 자기 뒷사람에게만 연락할 수 있다!
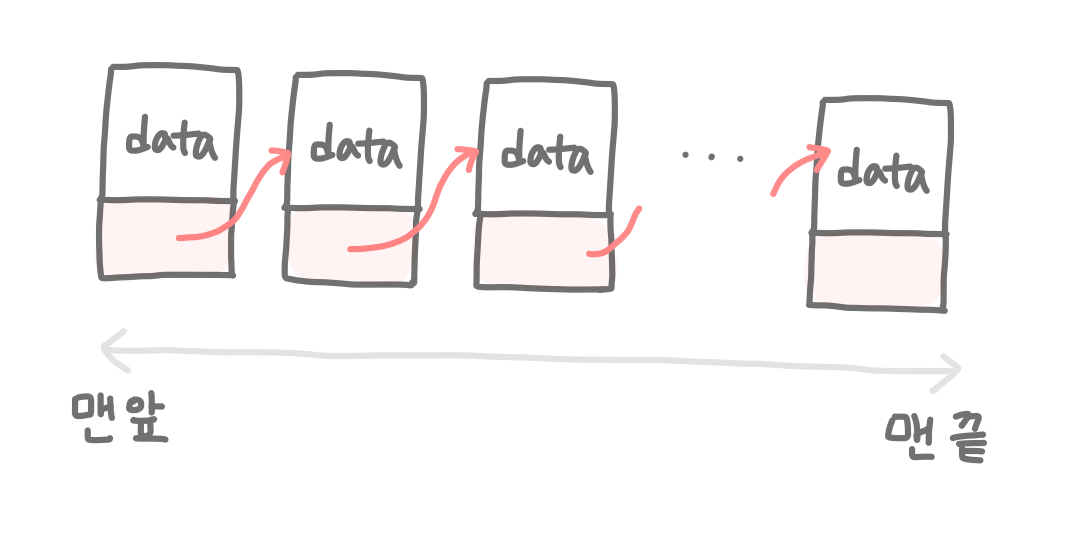
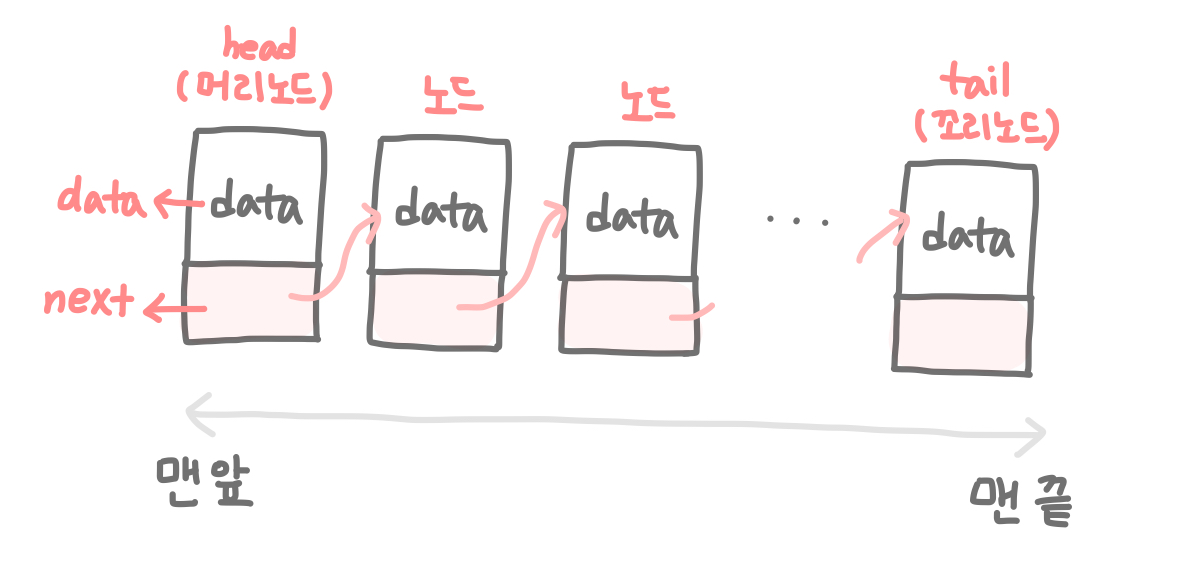
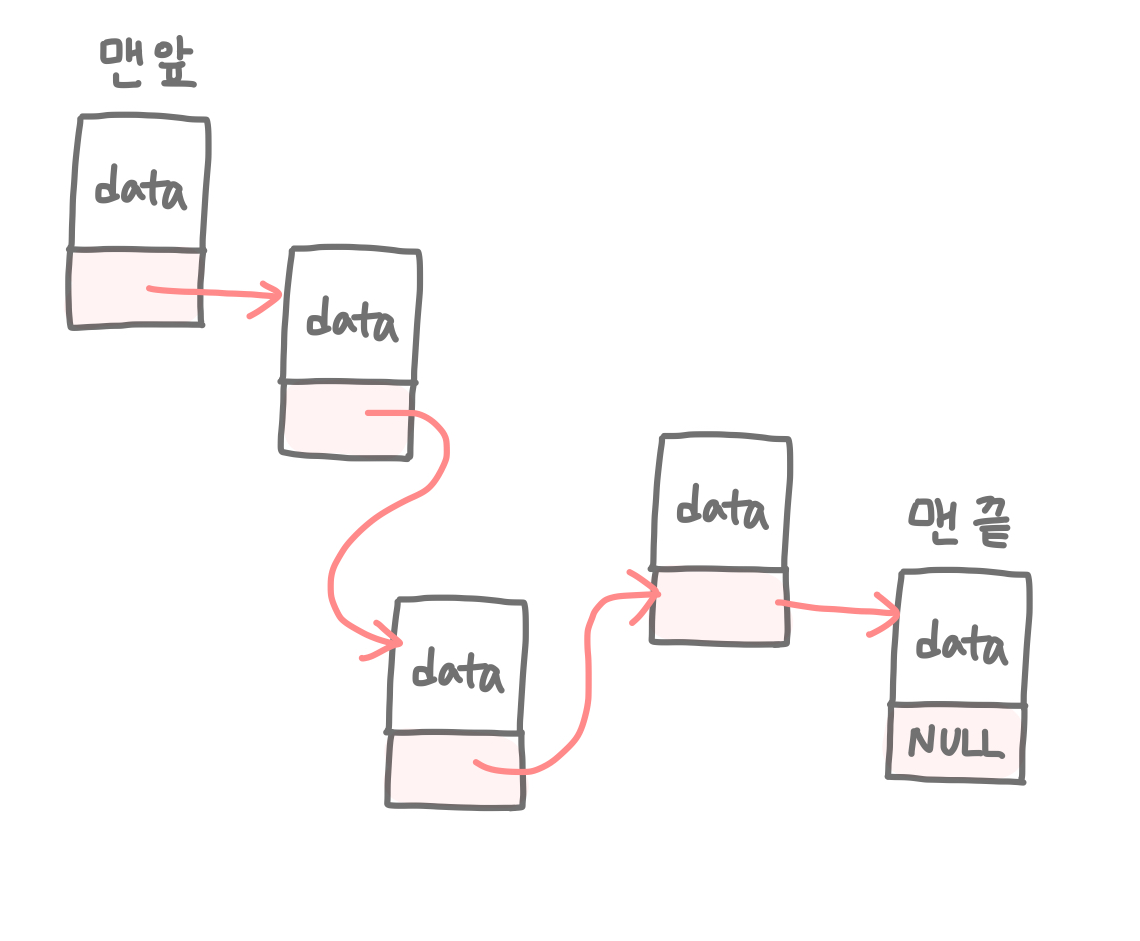
조금만 더 자세히 살펴보자. 연결 리스트에 일렬로 연결된 데이터들을 각각 노드(node)라고 한다. 그리고 이 노드들은 각각 1) 데이터(data)와 2) 다음 노드 정보(next)를 갖는다.
✔️ 노드(node) = 데이터(data) + 다음노드정보(next)
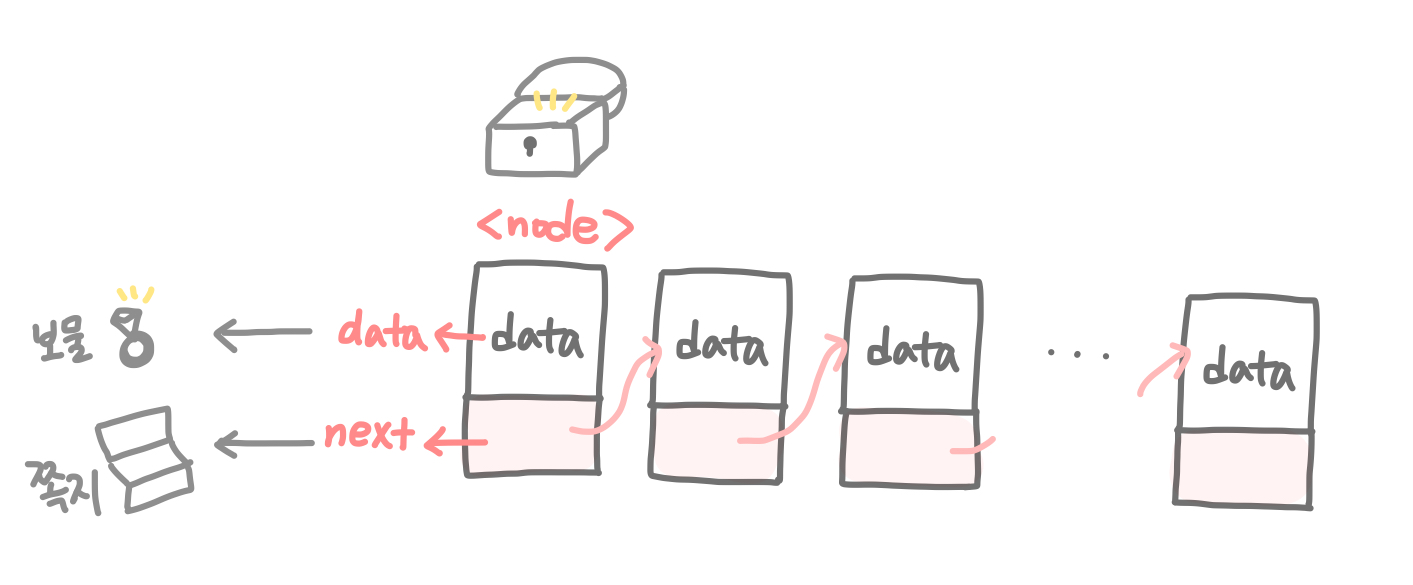
지금까지의 이야기를 보물 찾기에 비유해서 생각해보자. 노드는 보물상자, 데이터(data)는 보물상자 안의 보물, 다음 노드의 정보(next)는 다음 보물 위치를 알려주는 쪽지라고 생각할 수 있다!
노드(node) = 보물상자
데이터(data) = 보물
다음노드정보(next) = 다음보물 위치를 알려주는 쪽지
이제 대략 감을 잡았으니(?) 본격적으로 연결리스트에 대해 알아보자. 노드..넥스트..등 갑자기 새로운 용어가 쏟아질 수 있으니 꼭 그림을 보거나 그리면서 이해하자! 연결리스트는 한마디로 노드(node)로 이루어진 자료 구조이고, 각 노드는 index를 갖지 않는다. 리스트는 배열과는 달리 오직 원소(node)들 간의 논리적인 순서에 대한 정보만 가진 자료구조이기 때문에 자기 다음 데이터(next)가 무엇인지만 알고있다.
근데 이렇게 다른 데이터와 연결되려면 노드(node) 어딘가에 다음 데이터에 대한 정보를 기억하고 있어야 하지 않을까? 이렇게 자기 다음 데이터의 정보를 가지는 변수를 보통 '포인터 변수'라고 하는데 여기서는 next라는 변수가 이에 해당한다. 노드에는 자기자신의 값이 담긴 데이터(data)변수, 그리고 다음 데이터를 가리키는 포인터변수(next)가 들어있다.
그리고 연결 리스트의 맨 처음의 노드를 머리노드(head)라고 하며, 마지막 노드를 꼬리노드(tail)이라 부르기도 한다. 꼬리노드(tail)는 맨 뒤에 위치했기 때문에, 뒤에 아무도 없는 상태이다. 따라서 꼬리노드(tail)의 next변수에는 null이 들어가게 된다.
시간 복잡도 (Big-O)
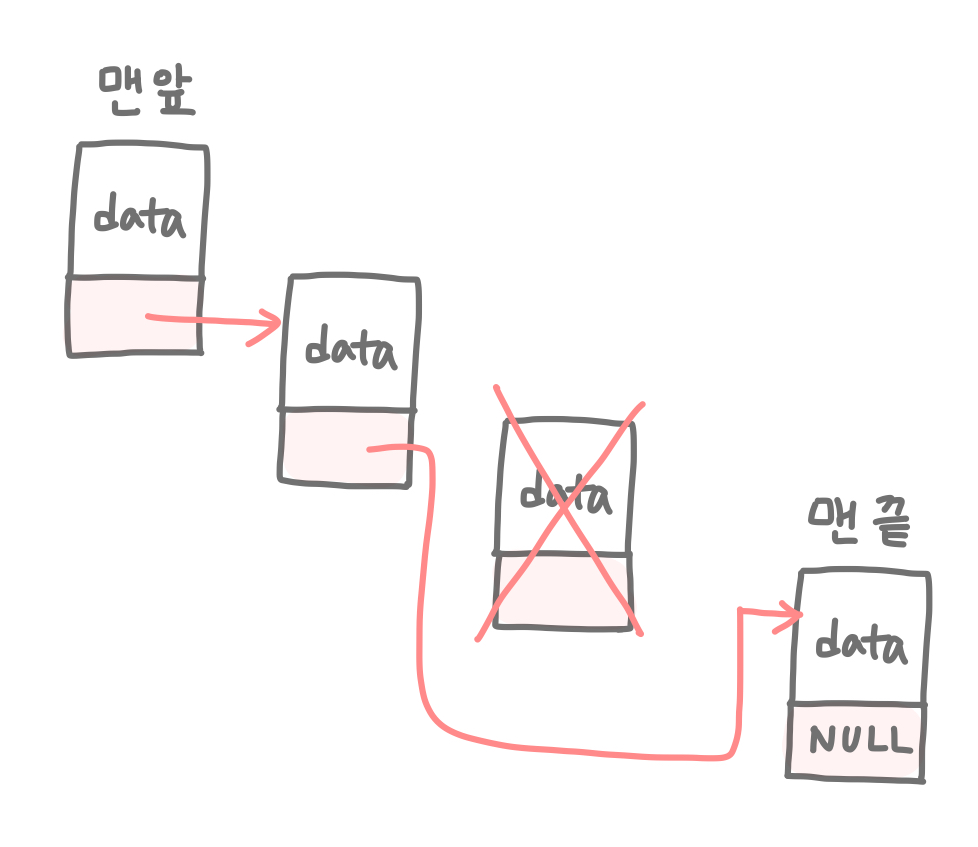
[추가/삭제] 이런 연결리스트가 생겨난 이유는 뭘까? 연결리스트는 데이터를 추가하거나 삭제할 때 효율적이기 때문이다. 탐색 과정 이후에, 임의의 지점에 데이터를 추가하거나 삭제는데는 O(1)의 시간이 걸린다. 하지만 엄밀히 말하면 경우에 따라 다르다고 하는게 맞고, 대부분의 경우 O(n)의 시간이 걸린다고 본다. 이 부분은 탐색과 함께 좀 더 설명하도록 하겠다.
[탐색] 위에서 한가지 주의해야 할 점은 '탐색 과정 이후'라는 말인데, 연결리스트는 순차 접근 방식을 사용해 탐색을 하기 때문에 앞선 노드들을 모두 거쳐야만 해당 노드의 데이터를 알 수 있다. 그래서 탐색은 최악의 경우 O(n)의 시간이 걸리게 된다. 그래서 결국 추가, 삭제 자체는 O(1)이 걸리지만, 전체적인 관점에서 본다면 탐색과정 이후에 일어나기 때문에 O(n)이라는 시간이 걸릴 수 있게 되는 것이다.
연결리스트 vs 배열
연결리스트는 특히나 배열과의 차이점에 대해 아는 것이 중요하다. 삽입과 삭제가 자주 필요한 상황에는 LinkedList(연결리스트)를 사용하는 것이, 데이터에 바로바로 접근하는 것이 중요한 상황이라면 Array(배열)을 사용하도록 하자!
| 연결리스트 (Linked List) | 배열 (Array) |
| 노드(node)들 간의 논리적인 순서에 대한 정보만 가짐 | 논리적 저장순서 = 물리적 저장 순서 |
| 사이즈 : 동적 노드가 추가됨에 따라 유연하게 사이즈가 바뀜 |
사이즈 : 정적 배열의 크기는 선언시 지정되어야 함 |
| 삽입 : O(n) (맨 앞, 맨 뒤에만 삽입하면 O(1)) |
삽입 : O(n) 새로운 원소를 추가하고 모든 원소들의 index를 옮겨야함 |
| 삭제 : O(n) (맨 앞, 맨 뒤에서만 삭제하면 O(1)) |
삭제 : O(n) 삭제한 원소 이후 index의 원소들을 옮겨야함 |
| 검색 : O(n) 순차 접근 방식(처음부터 차례로 검색) |
검색 : O(1) index알면 바로 원소 접근 가능 (Random Access) |
| 메모리 : 동적 메모리 할당 노드 추가 시 Runtime에 할당, Heap영역에 메모리 할당 |
메모리 : 정적 메모리 할당 |
더 알아보기
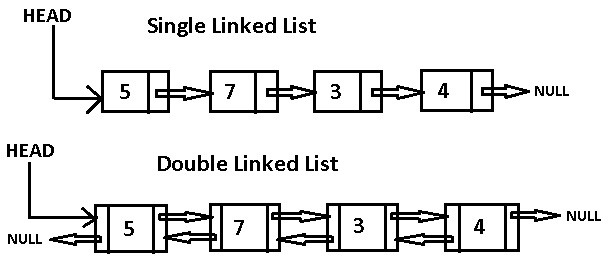
이제야 말하지만 지금까지 봐온 연결리스트는 사실 단일 연결 리스트(Singly-Linked List)였다. 연결 리스트에는 단일리스트 뿐만 아니라 이중 연결 리스트(Doubly-Linked List) 같은 더 다양한 형태도 존재한다. 단일 연결 리스트는 다음 노드의 정보(node)만 알고 있는 한 방향으로 연결된 구조인 반면, 이중 연결 리스트는 각 노드가 이전 정보(previous)와 다음 정보(next)를 모두 가진 양 방향으로 연결된 구조이다. 당연히 양쪽으로 접근이 가능한 이중 연결리스트가 더 좋은게 아닌가? 싶을 수 있지만, 더 많은 정보를 가진만큼 단일 연결 리스트보다 메모리를 더 잡아먹는다는 단점도 분명히 존재한다. 모든 상황에 딱 맞는 완벽한 자료구조는 없다. 모든 기술은 trade-off다..!
'Base > 자료구조' 카테고리의 다른 글
| Data Structure(5) Tree(트리), Binary Search Tree(이진검색트리) (0) | 2021.01.22 |
|---|---|
| Data Structure(4) Graph(그래프) (0) | 2021.01.22 |
| Data Structure(3) Hash Table(해시 테이블) (0) | 2021.01.21 |
| Data Structure(1) Stack (스택), Queue (큐) (0) | 2021.01.19 |




댓글